
Vom Datenchaos zur Datenklarheit: PDF-Formate in der Belegverarbeitung

Barrieren und Herausforderungen im Belegaustausch
Besonders unstrukturierte Belege, wie das PDF (Portable Document Format) erweisen sich dabei als eine fast unüberwindbare Hürde für Unternehmen. Denn bei unstrukturierten Belegen verlagern sich die verschiedenen Belegpositionen je nach Unternehmen und verwendetem Layout. Diese enthalten oft vielschichtige und verschachtelte Informationen und werden aufgrund der Komplexität nicht selten an Mitarbeitende delegiert, um die Daten manuell, aber kontextualisiert zu übertragen – und das im Zeitalter der fortschreitenden Digitalisierung. Dieser Prozess ist nicht nur zeitaufwendig und fehleranfällig, sondern auch ein wahres Produktivitätshemmnis.
Die Komplexität des Belegaustauschs wird durch unterschiedliche Systeme und Datenformate weiter verschärft. Große ERP-Systemanbieter haben bisher wenig Initiative gezeigt, den Datenfluss zwischen verschiedenen Systemen zu erleichtern. Dies entkoppelt Unternehmen durch eine unsichtbare Datenbarriere von der Außenwelt. Während interne Prozesse optimiert und skalierbar gemacht wurden, verkommen dabei auch strategische Partnerschaften und neue Handelsbeziehungen oft zu bloßen Absichtserklärungen. Doch wie lässt sich diese Barriere überwinden um einen Zustand der Flexibilität, Effizienz und Freiheit im Belegaustausch zu erreichen?
Die Scheinlösung heißt Optical Character Recognition (OCR)
Selbst hoch entwickelte Large–Language–Modelle (LLM), wie beispielsweise ChatGPT, stoßen an ihre Grenzen, wenn es darum geht, prozessuale und kontextübergreifende Informationen aus diversen Verarbeitungsschritten in einem ganzheitlichen Algorithmus zu vereinen. Die Bewältigung des Datenchaos erfordert mehr als nur die Fähigkeit, Inhalte zu erkennen und Daten zu extrahieren. Es bedarf einer intelligenten Lösung, die nicht nur angibt, welche Daten extrahiert werden sollen, sondern auch Kontextinformationen liefert, um die Daten korrekt zu verstehen und sie im richtigen Feld des Systems zuzuordnen.
Intelligent Data Interchange (IDI) bringt Ordnung in das Datenchaos
Die gute Nachricht: Es gibt eine effizientere Lösung, als mehrere Schritte zurück in der digitalen Revolution zu gehen und Belege manuell zu übertragen. Die KI-basierte Technologie dara® ermöglicht dabei die Verarbeitung von Daten aus strukturierten und unstrukturierten Belegen mittels intelligentem Datenaustausch, auch Intelligent Data Interchange (IDI) genannt. Dadurch eröffnet sich ein ganzheitlicher Ansatz in der Belegverarbeitung, welcher verschiedene Prozessschritte, von der Datenextraktion bis zur Datenintegration, abdeckt. Dieser Ansatz verspricht eine effizientere und intelligentere Verarbeitung von Dokumenten, bei der menschliche Intervention nur minimal erforderlich ist und schafft somit absolute Klarheit in das Datenchaos der Belegverarbeitung.
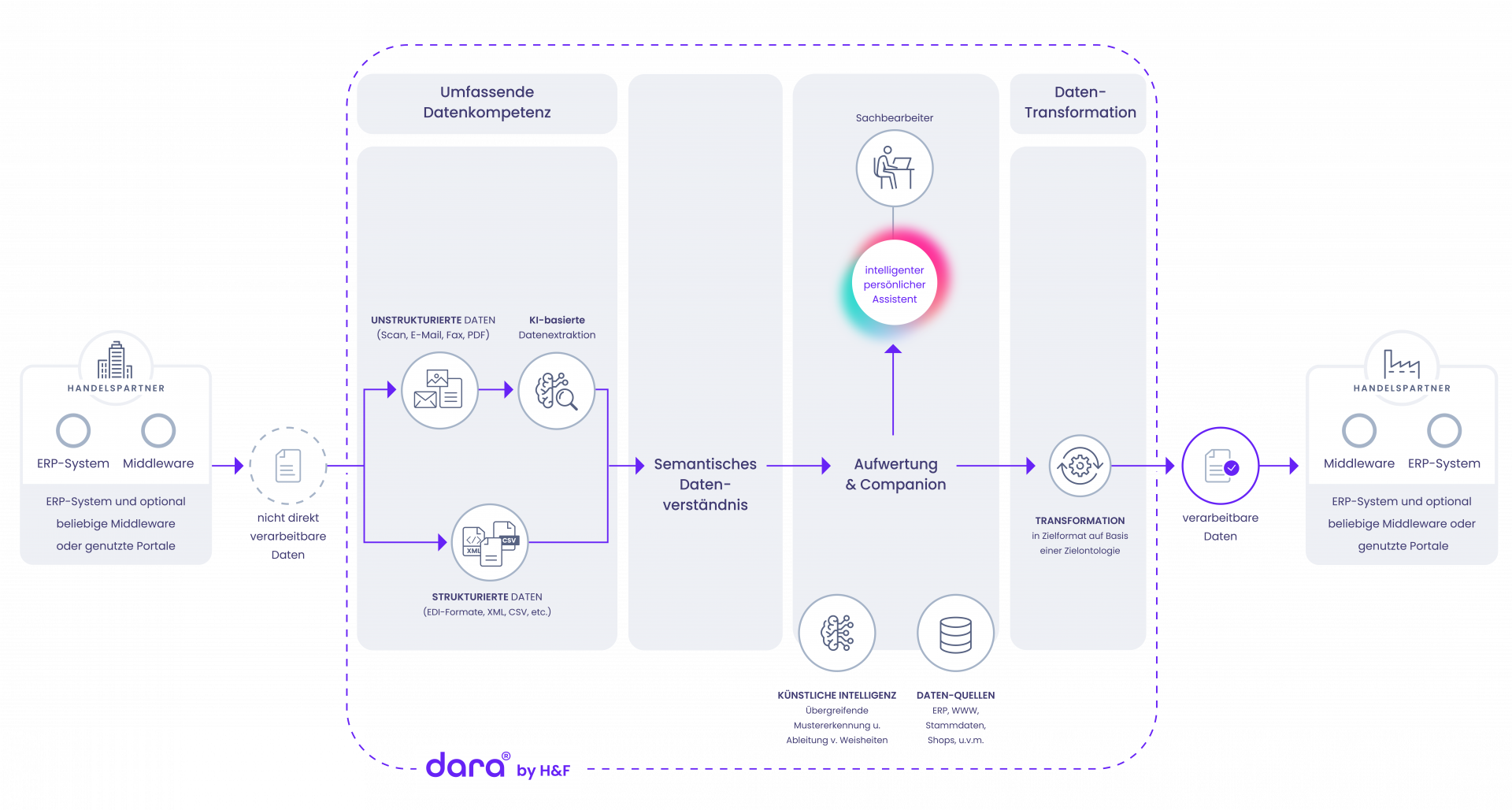
Der automatisierte Datenaustausch zwischen ERP-Systemen wird durch dara® mittels Intelligent Data Interchange ermöglicht. Dabei können sowohl unstrukturierte Daten als auch strukturierte Daten verarbeitet werden. Zu den unstrukturierten Formaten gehören dabei beispielweise PDF, Scan oder Fax.
Die Extraktion relevanter Informationen aus unstrukturierten Dokumenten erfolgt zunächst mittels KI-basierter Datenklassifizierung. Dabei werden nicht nur die erforderlichen Informationen identifiziert, es wird auch eine Struktur für die weitere Verarbeitung geschaffen. Nach der notwendigen Kontextualisierung werden die Daten anschließend mittels patentierter Datenanreicherung optimiert. So werden beispielsweise fehlende Artikelnummern oder Adressdaten ergänzt, homogenisiert und korrigiert. Dazu werden unter anderem externe Datenquellen einbezogen. Mittels dieser patentierten Verfahren ist dara® in der Lage, Datenlücken zu schließen, die Prozesseffizienz zu steigern und Prozesskosten zu verringern.
Durch die daraus resultierende höhere Datenqualität sind weniger manuelle Eingriffe notwendig und die Rückmeldung der Mitarbeitenden wird nur bei spezifischen Fällen proaktiv und interaktiv durch das System angefragt. Mittels des gegebenen Feedbacks lernt das System wiederum dazu und kann den Automatisierungsgrad weiter steigern. Das bedeutet: Auf Basis des Feedbacks, kann dara® die abgefragte Entscheidung in Zukunft selbst treffen und übernimmt die Position als intelligenter, virtueller Assistent. Im Anschluss wird die Transformation der Daten in das Zielformat auf Basis der vorgegebenen Zielontologie vorgenommen und diese für das Ziel-ERP-System bereitgestellt.
Der ganzheitliche Ansatz von dara® deckt alle Prozessschritte ab, minimiert die Notwendigkeit menschlicher Intervention und ermöglicht die einfache Anpassung an individuelle Anforderungen bezüglich Korrektur von Daten, Ausgangs- und Zielformate sowie Layout. Dadurch ist mittels Intelligent Data Interchange auch für unstrukturierte Belege ein Automatisierungsgrad von bis zu 99 % möglich.
Intelligenter Datenaustausch als Motor für den Unternehmenserfolg
Der hohe Automatisierungsgrad durch Intelligent Data Interchange (IDI) ermöglicht Unternehmen nicht nur eine enorme Steigerung der Effizienz, sondern auch eine Reduzierung der manuellen Eingriffe, was zu einer erheblichen Zeit- und Ressourcenersparnis beiträgt. Die Technologie vereinfacht das Onboarding neuer Geschäftspartner und verbessert die Verwaltung bestehender Geschäftsbeziehungen, indem sie ein gewisses Maß an Individualität der Nutzerparteien integriert und sich nicht mehr ausschließlich auf die Synchronität der Stammdaten verlässt. Dadurch wird die Art und Weise, wie Belege verarbeitet werden, auf das nächste Level gehoben.
Dies läutet im Bereich der Belegverarbeitung von strukturierten und unstrukturierten Formaten eine Ära der Datenklarheit und des automatisierten Datenaustauschs ein. Mit einem jährlichen Marktwachstum von 2 % im Belegaustausch zwischen Unternehmen ermöglicht dara® mittels Intelligent Data Interchange, das Datenchaos in eine Zukunft der Klarheit, Effizienz und Skalierbarkeit zu transformieren.
Ähnliche Beiträge

Wie KI und Intelligent Data Interchange den Belegaustausch transformieren
Mit Blick auf den Datenaustausch unterstützen ERP-Systeme Unternehmen seit Jahrzehnten bei der Rationalisierung ihrer zentralen internen Geschäftsprozesse. Zahlreiche dieser Prozesse werden bereits durch den gezielten Einsatz von Künstlicher Intelligenz unterstützt....

E-Rechnung – standardisiert empfangen, effizient verarbeiten
Einführung der E-Rechnung: Seit 1. Januar 2025 Pflicht Seit Anfang des Jahres gilt in Deutschland die Pflicht zur Nutzung der E-Rechnung für inländische B2B-Transaktionen. Unternehmen müssen nun elektronische Rechnungen im strukturierten Format gemäß der EU-Norm (z....

Effizienzsteigerung in der Fertigung durch intelligenten Datenaustausch
Seit Jahrzehnten tragen ERP-Systeme in der Fertigungsindustrie maßgeblich zur Optimierung interner Unternehmensprozesse bei. Durch den Einsatz Künstlicher Intelligenz (KI) lässt sich der Datenaustausch zwischen diesen Systemen weiterentwickeln, wodurch die Effizienz...